Introduction
Personal protective equipment (PPE) is a critical tool for workers in construction, manufacturing, and other industries. PPE helps protect workers from injury and illness by providing a barrier between the worker and potential hazards. However, ensuring that workers are wearing the correct PPE can be challenging, especially in large industrial settings.
Workers’ PPE are often checked manually by supervisors, which can be time-consuming and prone to error. In this article, we explore the use of computer vision to recognize personal protective equipment in industrial settings. By using computer vision, we can automate the process of checking workers’ PPE and ensure that workers are properly protected.
According to the Occupational Safety and Health Administration (OSHA), workers’ PPE consists of equipment such as helmets, masks, eye protection, gloves, high-visibility clothing and boots. In this article, we focus on the recognition of helmets and high-visibility clothing, which are commonly used in construction and manufacturing settings.

As you can see in the image above, the worker is wearing a helmet and high-visibility clothing. Our goal is to develop a computer vision model that can automatically recognize the presence of these items in images of workers.
TL;DR: You can find the repository for this project at ruhyadi/vision-ppe for the API engine and ruhyadi/model-ppe-cls for the classifier model.
The Models
We try to approach the challenge of PPE recognition as a detector-classifier problem. We first detect the presence of a person (worker) in the image using a pre-trained object detection model. Once we have detected a person, we crop the region of interest around the person and pass it through a classifier to recognize the PPE.
We fall in love with the YOLOX model, which is an anchor-free, one-stage object detection model that is fast and accurate. We use the YOLOX model to detect the presence of a person in the image.
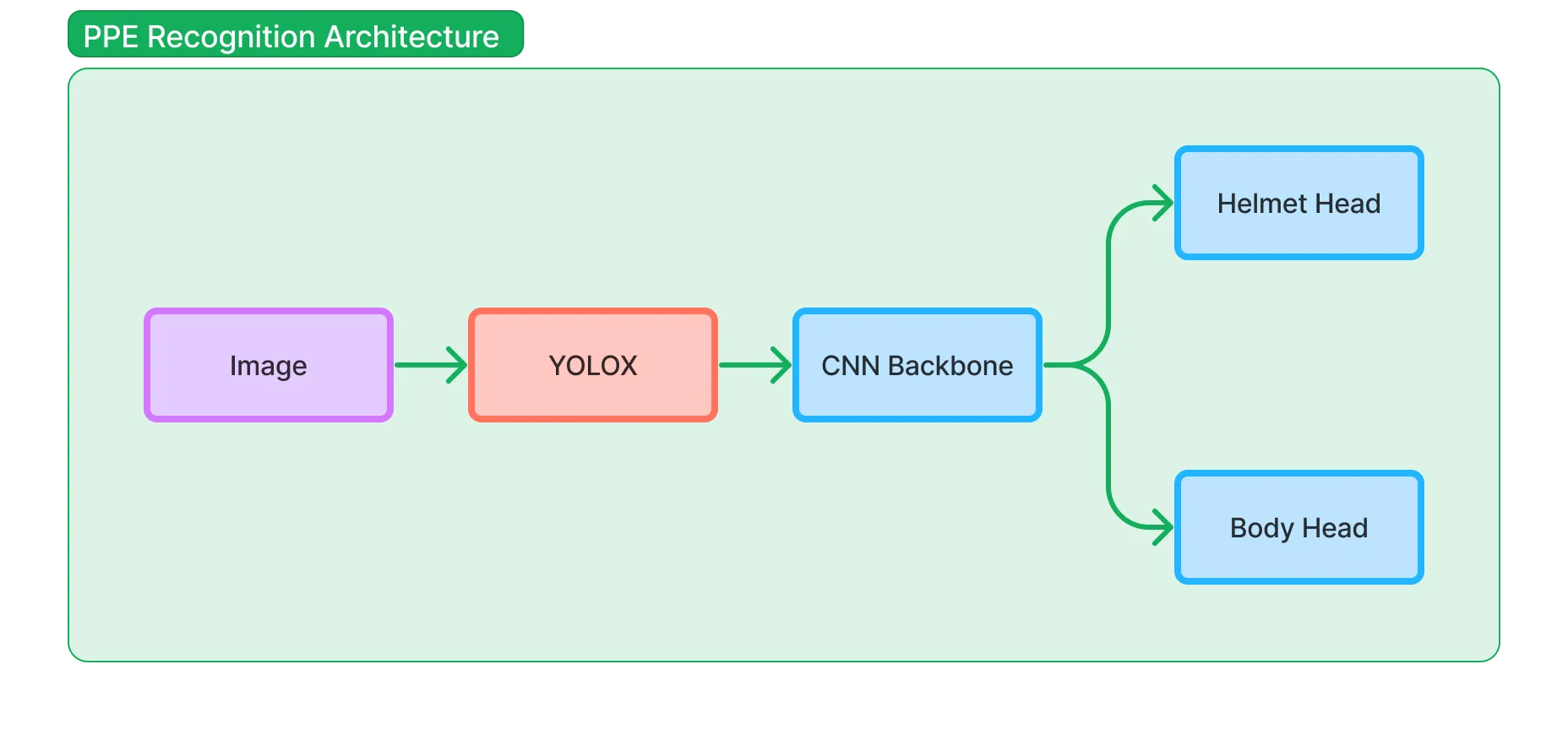
For the classifier, we use a multi-head CNN approach. We use well-known architectures such as ResNet and MobileNet as the backbone and add multiple heads for helmet and high-visibility clothing recognition.
Multi-Head CNN
The multi-head CNN architecture consists of a shared backbone network and multiple head networks. The shared backbone network is responsible for extracting features from the input image, while the head networks are responsible for making predictions based on the extracted features.
We believe that the multi-head CNN architecture is well-suited for the PPE recognition task because it allows us to share the feature extraction process across different PPE categories while maintaining separate prediction heads for each category. With this approach we can have many pairs of prediction, like red helmet + orange vest, yellow helmet + green vest, etc.
In the ruhyadi/model-ppe-cls repository, we use PyTorch Lightning to train the multi-head CNN model. You can find the implementation of the model in the src/models/ppe_model_factory.py file.
class PpeMobileNetV3(nn.Module): """PPE mobilenetv3 module."""
def __init__(self, num_helmet: int, num_body: int, pretrained: bool = True) -> None: """Initialize PPE mobilenetv3 module.""" super().__init__()
if pretrained: self.model = models.mobilenet_v3_large(weights=MobileNet_V3_Large_Weights) else: self.model = models.mobilenet_v3_large()
self.input_features = self.model.classifier[0].in_features * 7 * 7 self.model = nn.Sequential(*list(self.model.children())[:-2])
# helmet cls head self.helmet_head = nn.Sequential( nn.Linear(self.input_features, 128), nn.ReLU(inplace=True), nn.Dropout(0.2), nn.Linear(128, num_helmet), )
# body cls head self.body_head = nn.Sequential( nn.Linear(self.input_features, 128), nn.ReLU(inplace=True), nn.Dropout(0.2), nn.Linear(128, num_body), )
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]: """Forward pass.""" x = self.model(x) x = x.reshape(-1, self.input_features)
helmet_out = self.helmet_head(x) body_out = self.body_head(x)
return helmet_out, body_outIn the code snippet above, we define a PpeMobileNetV3 class that implements the multi-head CNN architecture using a MobileNetV3 backbone. We cut the origianl MobileNetV3 model at the second-to-last layer (before average pooling layer) and add two fully connected layers for each prediction head. The model has two prediction heads: one for helmet recognition and one for high-visibility clothing recognition. The forward method takes an input tensor x and returns the predictions for helmet and high-visibility clothing.
The Dataset
We get the dataset from Construction Personal Protective Equipment (CPPE) dataset, you can find the dataset in Google Drive. After that, we semi-automaticly label the helmet and high-visibility clothing using the CVAT. With semi-automaticly, we mean that we use the trained YOLOX and PPE classifier model to detect and classify the helmet and high-visibility clothing first, then we refine the bounding box and the label manually. You can read the details about semi-automatic labeling in here.
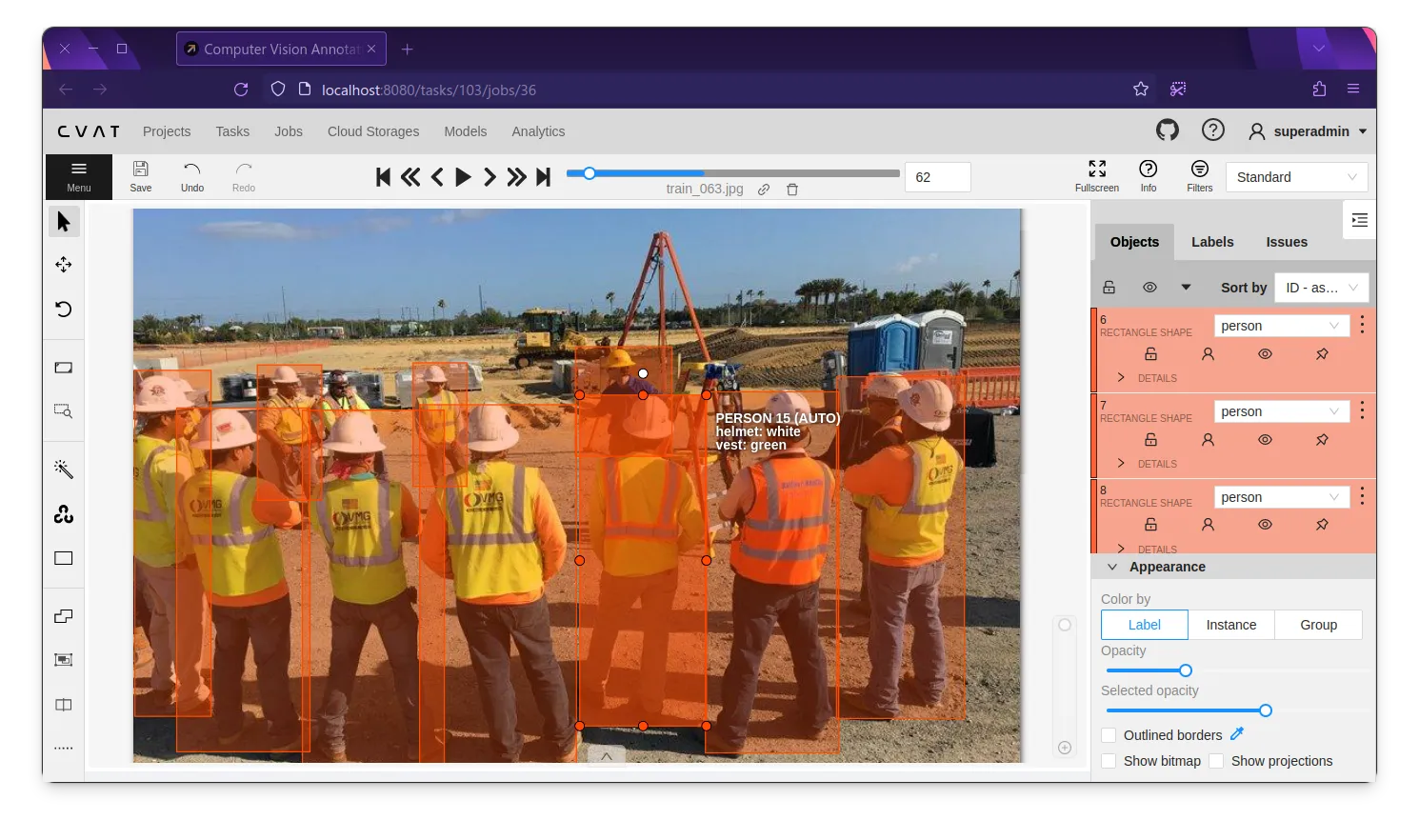
We have uploaded the labeled dataset to the ruhyadi/model-ppe-cls release. We have 395 training data and 45 validation data for helmet and high-visibility clothing recognition. The data is not balanced but it’s enough to show the proof of concept.
The API Engine
We’ve created the end-to-end pipeline for PPE recognition using the FastAPI and ONNX Runtime. You only need to pull the docker image and run the containers to start the API engine. Please refer to the ruhyadi/vision-ppe repository for the implementation details.
Conclusion
In this article, we explored the use of computer vision to recognize personal protective equipment in industrial settings. We developed a detector-classifier model that uses the YOLOX object detection model to detect the presence of a person in the image and a multi-head CNN model to recognize helmets and high-visibility clothing.